整个系列的文章从银行数据仓库架构,ETL,模型,数据管理以及几大方面应用介绍了数据仓库,可以让大家对银行数据仓库有个概要的了解。
前文回顾:
《银行数据仓库的系统架构是什么?看这篇足矣》
《深度分析|一文读懂银行数据架构体系》
《银行数据仓库都是这样的,一文了解》
但在各子系统设计,技术方面没有太深入介绍,后续也会陆续补充。作为这个系列文章的最后一节,简单谈谈对银行数据仓库发展的一些想法。
数据仓库作为银行数据中心,在这个大数据时代也发挥了重要的作用,那随着银行业业务系统架构的演变,特别是目前目前银行业务系统都在向采用微服务的分布式架构的转变,提高系统的吞吐量和运行效率,适应互联网高并发量和高用户数的特点。随之而来的可能有以下变化:
1.数据的分散化:
之前一个贷款系统包含贷前申请,贷中核额,贷后管理的并且还有许多实时查询,在微服务架构下,一个贷款系统可能会分成贷前,核额,贷后,前端(H5,app,pc)等业务系统,还会调用短信,签章,客户信息系统等多个关联系统。那一个业务流程的数据会分散到各个子系统中。
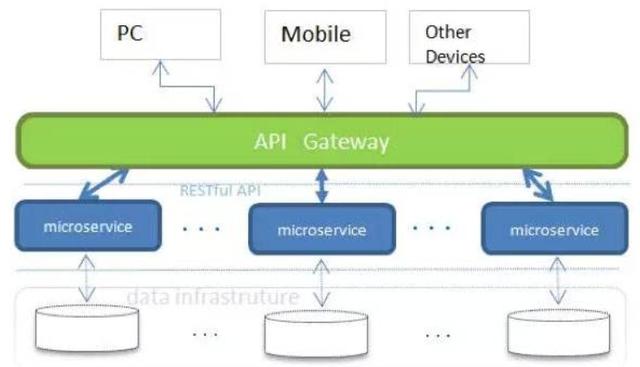
2.数据量增长:
银行通过多种自有互联网渠道(手机、公众号),以及通过与互联网平台合作、开放API等将在互联网扮演中后台的角色,即用户可能感受不到银行的存在,但是在使用银行的服务,如目前许多银行将自己的二、三类账户的能力提供给互联网公司,客户在互联网开立的账户其实是在其它银行开立的。因此银行的账户数以及客户量会快速增长,随之就是交易量的爆发。
3.数据应用的多样化:
随着大数据及AI技术的发展、数据应用将会大幅增长。同时实时应用和数据统计需求将会更多的出现,如风控、营销、投资决策、反欺诈等模型服务,如业务量的实时监控和实时预警等,目前FLINK、SPARK STREAM等实时数据处理平台发展也迅速。
大数据软件Finereport做出的双11大屏
数据的分散化和应用的多样化必然会带来数据需求的井喷,数据量的增长对技术平台的扩展性和性能要求将会更高,数据仓库也需要逐步进行架构和功能的演变,以适应业务发展需求:
1.技术平台方面将会出现更高性能和更大存储的技术平台
开源的HADOOP平台出现,降低了数据仓库以及大数据平台的技术门槛和成本,但在易用性和效率方面商用的版本或者大厂(google、Facebook、阿里、腾讯、华为等)的内部优化版本更有优势,后续双方也会互相借鉴,特别是一些大厂对开源社区的贡献将会促使更强大的数据处理技术平台出现。
2.数据仓库多集群化
随着数据量增加以及需求应用的增加,为降低耦合性以及提高灵活性,数据仓库不同功能会在分散到多个集群且不用集群技术平台可能也不同,如基础数据区,各数据集市,实时应用,历史数据,非结构化数据等可能都会单独建立集群,因此集群之间的数据快速交换也会要求更高。后续可能从底层存储复制或共享等方面有新的技术的出现。
3.数据仓库技能通用化
另外随着数据分散化以及应用的增多,为提高效率,会有多个团队在数据仓库上共同开发,数据仓库将会是一个基础平台和基本技能,因此需要做好资源隔离,同时需要将数据仓库的功能组件化,工具标准化,在全行或全公司的推广中减少学习成本,提高开发效率。
4.AI平台和数据仓库技术平台融合
AI后续将会逐步变为一个通用功能,hadoop生态目前也有支持机器学习的组件,如mahout、sparklib,但和专业的AI平台还是有算法、功能和性能的差距,AI平台也支持以hadoop作为数据处理平台,因此后续两者也会逐步融合,出现更智能的数据处理技术平台。
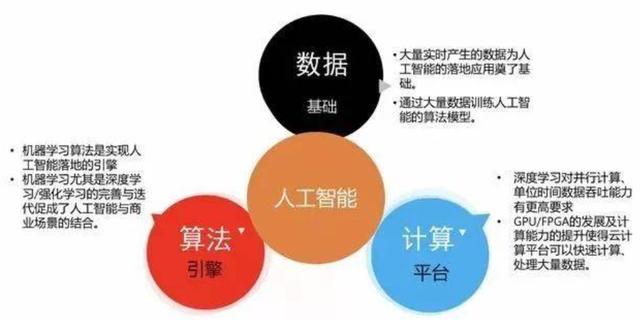
未来其实并不遥远,科技的世界里真的可以是一日千里。作为数据仓库开发、产品经理或者管理者,在做好平时工作的同时需要持续学习新的技术,以便在新的数据需求出现时有技术储备来提供高效的数据服务。
也需要熟悉数据内容以及在数据背后业务流程,发掘数据后面业务或产品的优化点。以终为始,促进业务和产品的发展。
