数据仓库管理着整个银行或公司的数据,数据结构复杂,数据量庞大,任何一个数据字段的变化或错误都会引起数据错误,影响数据应用,同时业务的发展也带来系统不断升级,数据需求的不断增加,数据仓库需要不断的升级和维护,才能保证为全行提供持续完整准确的数据服务。
所以数据仓库基本上是全行或全公司版本最多的系统,如何保证在频繁的变化中保证数据的准确和系统的稳定,需要数据仓库的开发管理必须做到高效、有条不紊。
1.1、规范先行
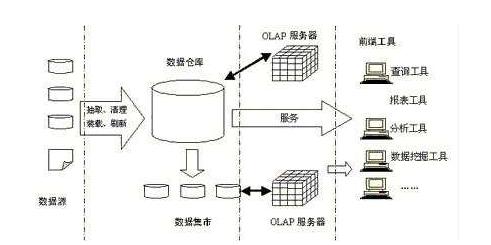
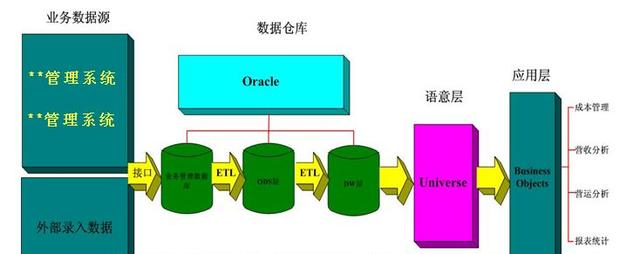
数据仓库从开发上看,数据加载和导入的程序相对固定,开发工作主要是数据转换的SQL脚本的分析和开发。那SQL的分析和开发最主要的还是基于业务逻辑进行编写,所以对数据字段的理解以及对业务规则的熟悉是数据仓库模型人员和开发人员都需要具备的知识,同时数据和规则又会不断变化,那如何确保快速开发,开发的代码具有可读性、模型设计具有一致性,最重要的是在数据仓库建立时就制定相应的规范,使整个团队能按规范同步进行开发、设计。那在数据仓库中主要有以下规范:
(1)命名规范:包括ETL作业、数据库或大数据平台的对象(表、字段、存储过程、schema名或库名)、脚本名、文件名等都需要按一定的规则进行命名,以便快速定位。
(2)ETL开发规范:包括抽取、加载作业的开发规范、调度工具的使用规范、SQL脚本或作业的开发规范、开发流程规范等:
(3)数据模型设计和维护规范:主要对主模型区、汇总指标层、集市层的模型设计原则、方法、重要规则(如客户ID)进行统一。
通过规范先行,能在数据仓库建设及后续维护中能快速统计数据仓库的运行情况,如系统作业的关键路径、表数量以及空间使用情况,源系统变化的影响情况等,避免产生混乱,比如许多数据仓库或系统随着不断变化和增加,连哪些表在使用,哪些数据已经不更新了、目标表使用了哪些源系统数据字段都不能马上分析出来,需要花费人力来梳理,一段时间后又回归混乱。这种情况不仅无法有效分析数据仓库的实际运行情况,更会带来生产问题的安全隐患。
1.2、开发流程
之前已经提到数据仓库从头建设的流程,那现在以某个数据应用对数据仓库提出需求来看整个系统维护的开发流程,主要步骤如下:
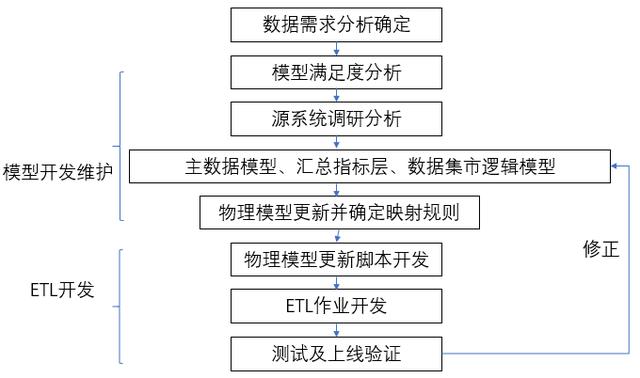
(1)需求分析:确定数据集市和数据仓库的接口字段和内容,明确数据需求;
(2)模型开发和维护:分析现有模型是否满足所有接口字段需求,如果不满足则需要从源系统增加入仓的表数据,并分析更新主数据区、汇总指标区和数据集市的逻辑模型、物理模型,并确定数据接口字段的映射关系,如果满足则只需确认映射规则;
(3)ETL开发:开发数据库或大数据平台的数据脚本以及作业脚本,并根据测试和生产验证的情况修正逻辑模型;
1.3、分工及职责
数据仓库团队主要分为模型人员、ETL开发人员和测试人员,其中模型人员主要是进行需求分析和模型维护,ETL开发人员负责代码实现和系统维护,开发流程中各角色工作如下:

那在许多银行实际开发中,根据公司团队规模不同模型人员的职责也会有所差别,模型人员有的属于数据仓库开发团队,只负责数据模型维护,有的属于科技规划团队即又称SA,模型人员除了模型维护可能还兼顾项目经理、系统分析的角色。那模型人员也可能分别负责主模型区、汇总指标区和数据集市。所以模型团队内部也需要定期同步数据模型的变化和更新,统一设计规则和数据分布边界;
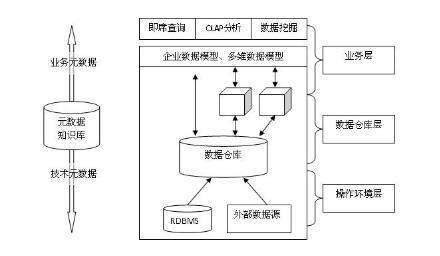
通过规范、标准流程和分工协作可以保证数据仓库开发工作有条不紊,但如何高效执行整个开发流程,提高代码开发效率。则需要有数据开发管理工具的支持。
之前在ETL开发中也介绍了一些开发实践,如标准的数据采集和加载作业、按ETL算法和数据映射自动生成数据转换脚本,那这些都可以通过工具整合并管理。通过开发管理工具对整个开发流程的模型数据、ETL数据和代码进行管理和维护,通过系统化来协助模型设计和开发,那对于一个数据仓库开发管理系统,主要有以下几方面功能:
2.1、数据模型维护功能
模型维护的功能许多是有文档来进行,通过系统的整合可以提高效率,增加信息的可统计性。
(1)对于源系统调研信息进行管理,可对源系统的每个表和字段调研备注信息进行存储修改,同时针对每个需求新增的表和字段都进行维护,以便沉淀经验。
(2)逻辑模型管理,这个功能如果已经是通过ERWIN或POWERDESIGN等工具进行管理,可以只将结果和历史版本进行维护。如果自己开发,可以集成一些开源工具的逻辑模型功能,统一在开发管理系统中维护。
(3)物理模型管理:物理模型主要是根据逻辑模型可以自动生成物理模型,模型人员和ETL开发人员在这个基础上进行物理化,增加索引、压缩、分区等信息。开发管理系统需要对物理模型进行存储和记录版本变更记录,那各个数据区的物理模型都可以在开发管理系统中维护,同时针对每次版本的变更,自动生成数据库或者大数据平台的数据库脚本。

2.2、ETL作业信息配置及代码生成
(1)数据映射:管理第5节介绍的数据转换作业映射文档,在配置算法等信息后,自动生成数据转化作业代码;
(2)数据采集和加载:管理数据采集作业和加载作业的信息,具体可见第4节,并自动生成采集和加载作业的脚本;
(3)调度作业:可以集成调度工具测试环境,根据ETL作业脚本信息,自动生成调度作业的脚本并同步作业信息到调度系统,并在调度工具中配置依赖关系后并测试后形成上线的调度作业配置版本。
2.3、打通测试环境和版本管理工具
数据仓库的代码主要是ETL脚本,无需编译,只需放在规范的目录下即可,由于生成代码后还需要提交到版本管理工具以及测试环境进行测试,因此可以直接调用版本管理工具的命令进行生成的代码更新,再通过版本发布工具发布到测试环境。如果没有版本发布工具,可以直接在开发管理工具中集成脚本传输的功能,在测试环境验证后再更新版本管理工具上的代码分支。
通过打通测试环境和版本管理工具,可以提高自动化,确保从系统自动产生代码和脚本,使维护的信息和生产脚本确保一致。
实际开发中,数据仓库可能会有多个团队进行维护,许多厂商也会有些工具,但要从数据仓库全开发流程以及结合各银行或公司的版本管理、测试管理流程来设计工具,提高开发效率这个层面,厂商一般不会考虑那么全面,需要银行数据仓库管理人员进行规划。通过统一规范及基础上通过开发管理工具可以更好的统一全行的数据开发规范,提高开发效率和代码质量,让更多的人力投入到数据应用开发和分析中。